Abstract
- 该模型通过捕捉笑话的不一致性(inconsistency,)、语音特征(phonetic features)和歧义(ambiguity)作为语义特征(semantic features)
- 该模型在三个公开可用的wisebrack数据集上进行了实验,效果优于SOTA模型
Introduction
- [研究方向、目的]:幽默是人类生活和交流中的一种重要调味剂, 而文本是传达幽默的重要媒介。在实际应用中,如果计算机能够识别幽默表达,那么作者的真实意图就可以被更准确地理解,从而使人机交互更有趣、更具吸引力。
- [卖点铺垫]:因此,在本文中,幽默识别任务侧重于短笑话,通常通过双关语、押韵和语义不一致来产生幽默。
- [卖点]:
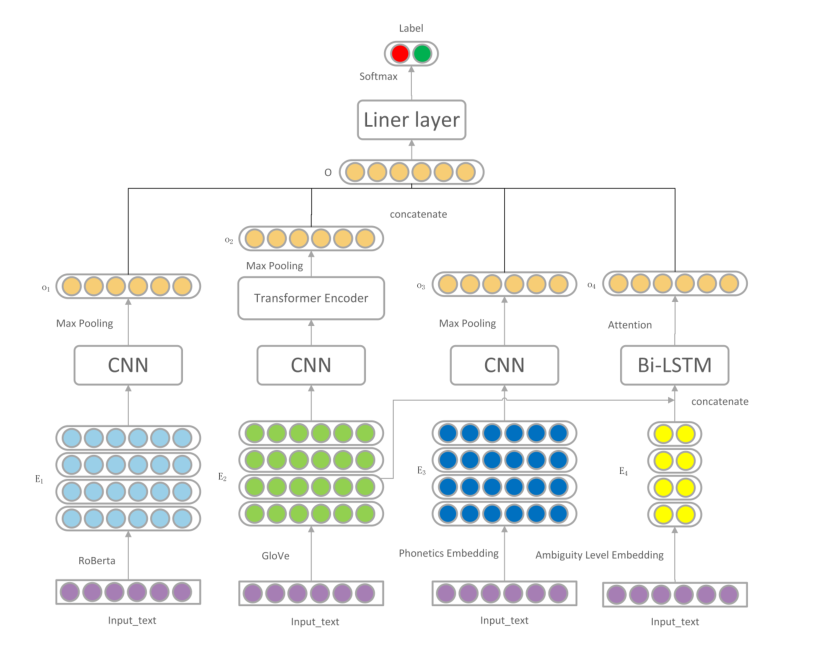
- 为了捕捉幽默的不一致性、模糊特征和语音特征,作者设计了一个模型。用RoBERTa + CNN来抽取幽默的片段嵌入(句嵌入);用Glove + CNN + Transformer Encoder来抽取语义不一致性特征;通过CMU的语音词典 + CNN来抽取语音特征;通过WordNet + BiLSTM + attention来抽取歧义特征
Analysis of Humor Features
Inconsistent Feature
Fuzzy Feature
- 幽默的关联理论(relevance theory)主要从自然语言中的一种常见现象,即歧义来探索和分析幽默。
- 产生歧义的主要原因是,一些单词具有表面看起来显而易见的意义,但是由于上下文的限制,这些单词产生了更加隐晦的含义。例如:“Did you hear about the guy whose whole left side was cut off? He’s all right now”. 在这句话种right除了表示“右边”这个显而易见的意思以外,跟all搭配还能表示“恢复”的意思。
- 通常引入WordNet,并比较其中包含的含义的最远路径和最近路径,从而实现歧义特征的发现。(???不太懂啊这里😅)
Phonetic Feature
- 其他幽默理论也表明,语音特性在产生幽默中也很重要。语音特性使文本原本就不幽默或有趣。笑话通常依赖于大声朗读,通过首韵、最高级、押韵等产生喜剧效果。类似的方法经常出现在报纸标题、赞美诗和顺口溜中。
- 卡耐基梅隆大学发音词典(CMU发音词典)可用于实现发音类别的幽默识别。